- 개요
- 개념 설명
- Async/sync, Blocking/Non-Blocking
- 동기(Synchronous)와 비동기(Asynchronous) 개념
- 블로킹(Blocking)과 논블로킹(Non-Blocking) 개념
- 동기/비동기, 블로킹/논블로킹의 차이
- SpringMVC vs Spring WebFlux
- SpringMVC
- Spring WebFlux
- Async/sync, Blocking/Non-Blocking
- 테스트 내용
- WebClient(비동기)? Spring WebFlux?
- 기본 구성
- 테스트
- SpringBoot 서버 => Spring WebFlux 서버 요청 코드
- Spring WebFlux 코드
- 기존 MVC 스타일 코드
- 리액티브 프로그래밍 코드
- 테스트 과정
- Request 세팅
- 테스트 결과(1 request)
- MVC 코드 방식 결과
- 리액티브 코드 방식 결과
- 테스트 결과(N건 request)
- 결론
개요
회사 관리자 프로젝트의 신규 개발 기능중에 고객사 쇼핑몰의 유저 데이터 Excel 파일을 업로드 하는 기능이 있었다.
업로드된 엑셀 파일을 CSV파일로 변환하고 DB에 데이터를 저장하는 로직이 필요했다.
중요한건 100만건 이상의 데이터를 처리할 수 있어야 한다는게 기획팀의 요청이었다. 엑셀 파일내 데이터 처리는 문제가 없었지만 대용량을 얼마나 빠르게 성공시키냐가 관건이었다..
100만건 이상 되는 데이터를 동기적으로 처리할 경우 클라이언트단에서 응답을 받는 시간도 느리고,
한 고객사가 아니라 여러 고객사가 동시에 요청이 들어올 경우 멀티 쓰레드라 할지라도 부하가 심해지는 단점이 생긴다고 판단했다.
개념 설명
Async/sync, Blocking/Non-Blocking
아래 링크에서 내가 정리한 내용을 볼 수 있다.
Async/sync, Blocking/Non-Blocking
동기(Synchronous)와 비동기(Asynchronous) 개념 동기는 요청과 그 결과가 동시에 일어난다는 뜻이며, 예를 들어 호출한 함수가 호출된 함수의 작업이 끝나서 결과값을 반환하기를 기다리거나, 지속적
honinbo-world.tistory.com
SpringMVC vs Spring WebFlux
SpringMVC
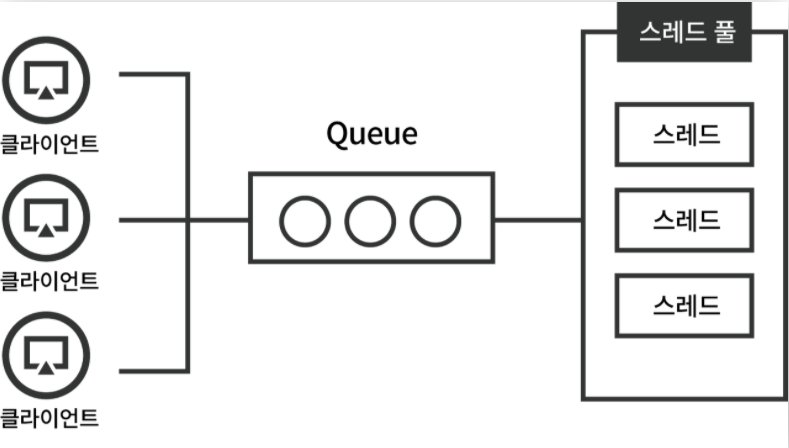
위 그림처럼 클라이언트로부터 요청이 들어오면 Queue를 통하게 된다. 스프링 어플리케이션은 요청당 Thread 한개가 할당된다.
즉 Thread Pool이 수용할 수 있는 요청까지만 동시적으로 작업이 처리되고 만약 넘게 된다면 큐에서 대기 하게 된다.
Thread 생성 비용은 크기 때문에 미리 생성하여 재사용함으로써 효율적으로 사용한다. 서버 성능에 맞게 Thread 최대 수치를 제한시키는 데, Tomcat 기본 사이즈는 200이다.
Spring WebFlux

위 그림은 WebFlux 구조에 대한 그림이다. 요청별로 Thread를 생성하는 것이 아니라, 다수의 요청을 적은 Thread로 처리를 한다. Worker Thread 기본 사이즈는 서버의 Core 개수로 설정되어있다.
이렇게 Non Blocking 방식을 활용하면 효율적인 I/O 제어가 되어 성능이 향상될 수 있다. 그래서 MSA에서 네트워크 호출이 많기 때문에 적용하기 좋다고 한다. 하지만 I/O 작업 중 하나라도 Blocking 방식이 있다면,
결국 Blocking이 발생되기 때문에 4개의 Thread 이후 요청은 결국 대기를 해야한다.
테스트 내용
WebClient(비동기)? Spring WebFlux?
테스트 과정에서 기존 예제들을 찾아보니, WebClient와 Spring WebFlux를 혼용해서 사용하는 방법도 있었고, 단순히 Spring WebFlux만 사용하는 방법도 있었다.
처음에는 WebClient 객체가
implementation 'org.springframework.boot:spring-boot-starter-webflux'webflux 의존성을 가지고,
org.springframework.web.reactive.function.client.WebClient;
WebFlux 패키지 하위의 객체였기 때문에 Spring WebFlux와 WebClient는 같이 사용해야 한다고 생각했다.
그러나 좀 더 살펴보니 WebClient를 사용하지 않고 동기적인 요청으로도 WebFlux를 사용할 수 있었다.
그래서 WebClient를 사용하지 않고 회사 프로젝트(SpringBoot)에 webflux 의존성을 추가해 혼용해보려고 했지만 SpringBoot Config와 WebFlux Config가 충돌해 혼용하는건 불가능한 것으로 테스트되었다.
기본 구성
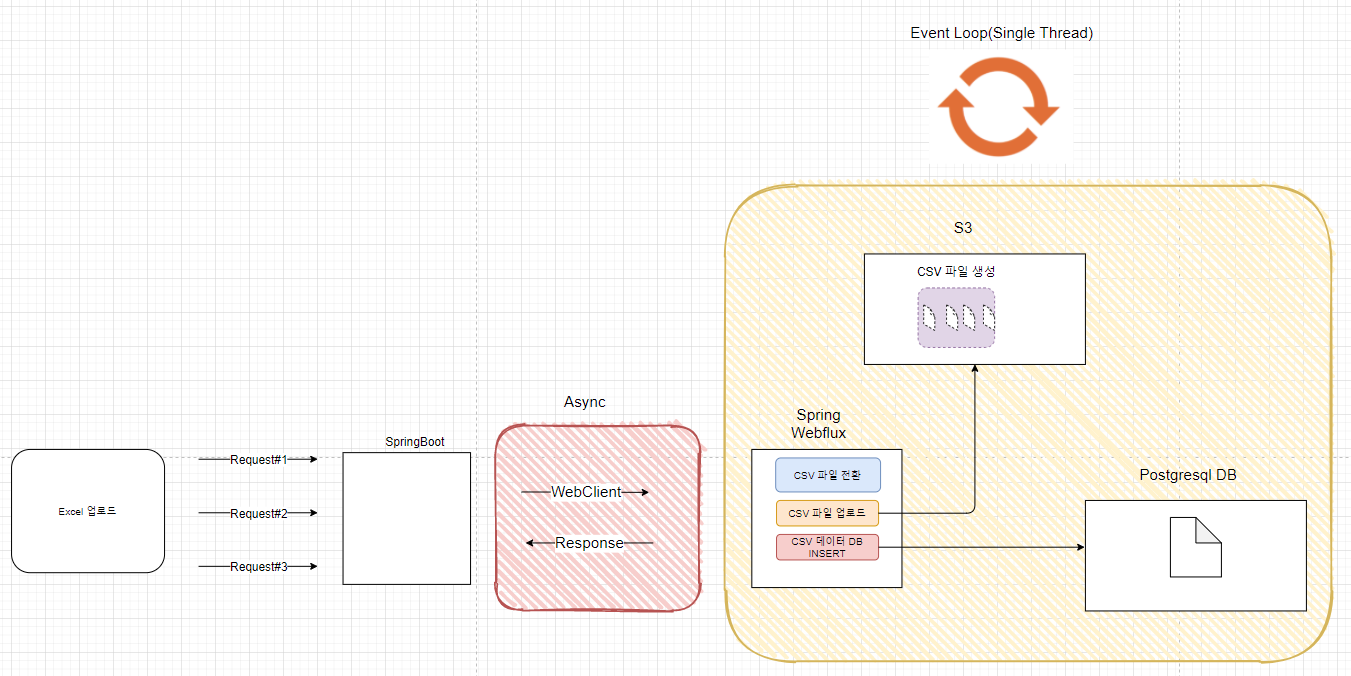
그림을 요약하자면,
- 프론트단에서 파일 업로드를 하면 SpringBoot(회사 프로젝트) 서버는 요청을 받아
- WebClient로 WebFlux서버에 비동기 통신을 하고
- 비동기 통신의 Response를 받아 프론트단으로 전달하고
- 파일 관련 Transaction은 WebFlux 서버의 싱글 스레드로 Event Loop 처리를 통해 N건의 요청이 오더라도 Blocking없이 효과적으로 처리할 수 있게 구성했다.
테스트
SpringBoot 서버 => Spring WebFlux 서버 요청 코드
@RestController
@RequestMapping("test")
public class TestController {
private WebClient webClient;
@Autowired
public TestController() {
this.webClient = WebClient.create("http://localhost:8082");
}
@PostMapping("webflux")
public String uploadFile_webflux(@RequestParam(value = "file") MultipartFile file) {
System.out.println("uploadFile_webflux 메소드 실행");
long startTime = System.currentTimeMillis();
Mono<String> result = webClient
.post()
.uri("/annotation/uploadExcelFile")
.body(BodyInserters.fromMultipartData(fromFile(file)))
.retrieve()
.bodyToMono(String.class);
// WebFlux 서버의 response를 받으면 subscribe의 callback 함수가 실행된다.
result.subscribe(arg -> {
long transactionEndTime = System.currentTimeMillis();
System.out.println("transaction 반환시간 : " + (transactionEndTime-startTime)/1000 + "초");
});
return "spring boot response ok";
}
private MultiValueMap<String, HttpEntity<?>> fromFile(MultipartFile file) {
MultipartBodyBuilder builder = new MultipartBodyBuilder();
// Excel 파일을 저장할 로컬 Path
String uploadedPath = "C:\\Users\\seail\\test\\" + LocalDateTime.now().format(DateTimeFormatter.ofPattern("HHmmss")) + "_uploaded_" + file.getOriginalFilename();
File convFile = new File(uploadedPath);
try {
convFile.createNewFile();
FileOutputStream fos = new FileOutputStream(convFile);
fos.write(file.getBytes());
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
builder.part("filePath", uploadedPath);
return builder.build();
}
}
프론트단에서 100만건 엑셀 파일이 업로드 되었을 때 실행되는 코드이다.
fromFile 메소드에서 업로드된 파일을 로컬 경로에 저장한 후, 로컬 경로 String을 body에 담아 WebFlux 서버에 전달한다.
Spring WebFlux 코드
흔히 우리가 알고 있는 MVC 방식 코드와 Spring WebFlux가 지향하는 리액티브 방식의 차이를 확인하기 위해 먼저 MVC 스타일 코드로 진행해보았다.
기존 MVC 스타일 코드
@Service
public class FileService {
....
....
....
public Mono<String> uploadExcelFile(String filePath) throws IOException {
// 엑셀 -> CSV 변환 측정
long startTime = System.currentTimeMillis();
File csvFile = xlsToCsv(filePath);
long excelToCsvEndTime = System.currentTimeMillis();
System.out.println("excel -> csv 완료시간 : " + (excelToCsvEndTime-startTime)/1000 + "초");
// CSV 파일 업로드 측정
String key = csvUpload(csvFile);
long uploadEndTime = System.currentTimeMillis();
System.out.println("csv 업로드 완료 시간 : " + (uploadEndTime-excelToCsvEndTime)/1000 + "초");
// CSV -> DB Insert 측정
executeDb(key);
long dbInsertEndTime = System.currentTimeMillis();
System.out.println("db insert 완료 시간 : " + (dbInsertEndTime-uploadEndTime)/1000 + "초");
return Mono.just("spring webflux response ok");
}
private File xlsToCsv(String filePath) throws IOException {
File excelFile = new File(filePath);
InputStream is = new BufferedInputStream(new FileInputStream(excelFile));
return ConvertUtils.xlsToCsv(is, "test_serviceKey");
}
private String csvUpload(File csvFile) {
String key = path + csvFile.getName();
awss3Util.upload(bucketName, key, csvFile);
return key;
}
private void executeDb(String key) {
String tableName = "tbl_excel_upload_ssi_test";
String csvPath = bucketName + "/" + key;
fileMapper.createUserListTable(tableName);
fileMapper.copyTableFromCsvUrl(tableName+"(member_id, phone_number)", csvPath);
}
}
각각의 트랜잭션(엑셀 파일 => csv파일 변환, s3 업로드, csv 데이터 db에 INSERT) 별로 결과 시간을 확인할 수 있다.
리액티브 프로그래밍 코드
@Service
public class ReactiveFileService {
....
....
....
public Mono<String> uploadExcelFile(String filePath) throws IOException {
return Mono.fromCallable(() -> {
logger.info("xlsToCsv 실행 쓰레드 : " + Thread.currentThread().getName());
return xlsToCsv(filePath);
})
.map(file -> {
logger.info("csvUpload 실행 쓰레드 : " + Thread.currentThread().getName());
return csvUpload(file);
})
.doOnNext(key -> {
logger.info("executeDb 실행 쓰레드 : " + Thread.currentThread().getName());
executeDb(key);
})
.subscribeOn(Schedulers.elastic())
.switchIfEmpty(Mono.error(new RuntimeException("mono error")))
.doOnError(e -> logger.info(e.getMessage()));
}
private File xlsToCsv(String filePath) throws IOException {
File excelFile = new File(filePath);
InputStream is = new BufferedInputStream(new FileInputStream(excelFile));
return ConvertUtils.xlsToCsv(is, "test_serviceKey");
}
private String csvUpload(File csvFile) {
String key = path + csvFile.getName();
awss3Util.upload(bucketName, key, csvFile);
return key;
}
private void executeDb(String key) {
String tableName = "tbl_excel_upload_ssi_test";
String csvPath = bucketName + "/" + key;
fileMapper.createUserListTable(tableName);
fileMapper.copyTableFromCsvUrl(tableName+"(member_id, phone_number)", csvPath);
}
}
Mono.fromCallable으로 Callback 메소드를 등록할 수 있다.
subscribeOn은 Callback 메소드를 실행시킬 쓰레드를 지정하는 메소드이다.
쓰레드를 실행시킬 수 있는 스케줄러 옵션은 몇 가지 있다.
- Schedulers.immediate() : 현재 쓰레드에서 실행한다.
- Schedulers.single() : 쓰레드가 한 개인 쓰레드 풀을 이용해서 실행한다. 즉 한 쓰레드를 공유한다.
- Schedulers.elastic() : 쓰레드 풀을 이용해서 실행한다. 블로킹 IO를 리액터로 처리할 때 적합하다. 쓰레드가 필요하면 새로 생성하고 일정 시간(기본 60초) 이상 유휴 상태인 쓰레드는 제거한다. 데몬 쓰레드를 생성한다.
- Schedulers.parallel() : 고정 크기 쓰레드 풀을 이용해서 실행한다. 병렬 작업에 적합하다.
Schedulers.elastic()을 사용해 데몬(워커) 쓰레드를 생성해 Non-Blocking 방식으로 처리할 수 있게 진행했다.
테스트 과정
Request 세팅
엑셀 샘플 파일 세팅

Postman 세팅
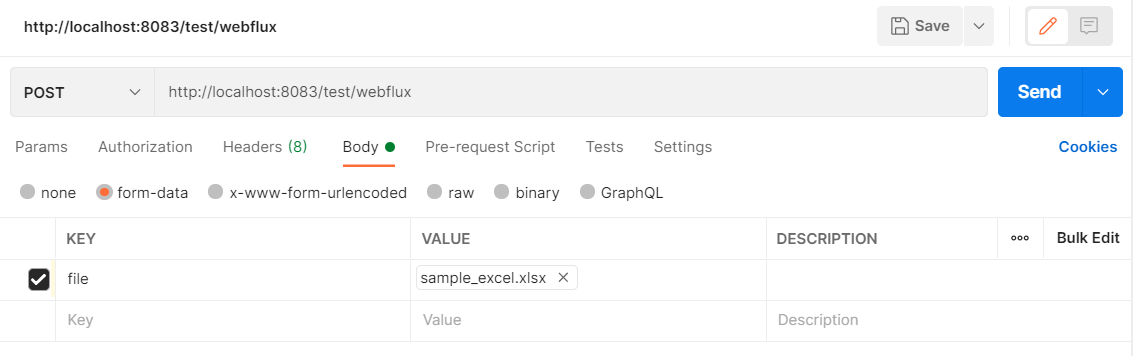
클라이언트 툴(Postman 등)을 이용해 SpringBoot 서버로 날릴 Request를 설정한다.
Send를 눌러 요청을 날려보면
테스트 결과(1 request)
MVC 코드 방식 결과

클라이언트가 Response 결과값을 받는 시간은 1268ms 정도 걸린다.

Spring WebFlux가 엑셀 관련 트랜잭션을 완료시키는 시간은 총 32초 정도 걸리는 듯 하다.

Spring WebFlux가 엑셀 관련 트랜잭션을 완료하고 SpringBoot가 Response를 받는 시간은 총 35초 걸리는 듯 하다.
리액티브 코드 방식 결과

클라이언트가 Response 결과값을 받는 시간은 678ms 정도 걸린다.
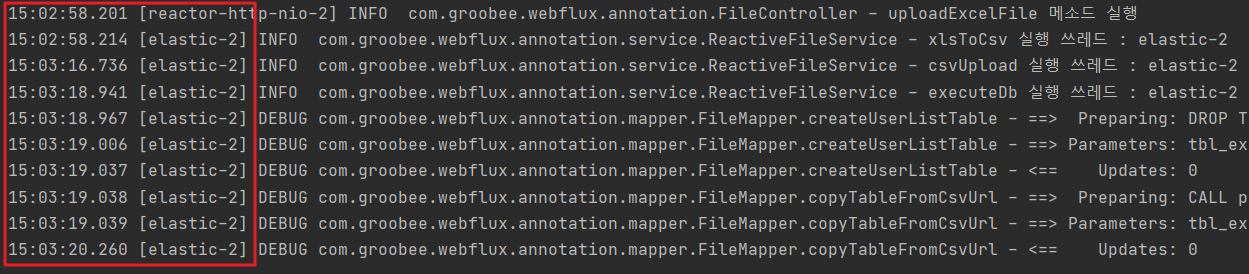
빨간색 박스 처리된 곳을 살펴보면, 메인 쓰레드 외에 elastic 이라는 이름의 데몬 쓰레드가 실행되는걸 볼 수 있다.
실행 시간을 살펴보면, 엑셀 관련 트랜잭션을 완료시키는 시간은 총 22초 정도 걸리는 듯 하다.

Spring WebFlux가 엑셀 관련 트랜잭션을 완료하고 SpringBoot가 Response를 받는 시간은 총 22초 걸리는 듯 하다.
테스트 결과(N건 request)

MVC 방식, 리액티브 코드 방식 둘 다 Request가 2번 이상부터는 Java Heap Size Overflow가 발생했다.
결론
WebClient를 통해 비동기 통신을 하기 때문에 클라이언트단에서 Response 값은 빨리 받아올 수 있어 화면상 프리징 상태가 발생하는 것은 해결할 수 있다.
하지만 화면의 프리징 문제만 해결하려면 WebClient만 써도 충분할 듯 하다.
원래 목적인 Spring WebFlux 구현 테스트 결과를 살펴보면, MVC 방식과 리액티브 방식의 결과가 상이한 것을 볼 수 있다.
리액티브 방식으로 Non-blocking 처리를 하게 되면 처리 속도가 더 빨라진다는게 이번 테스트로 증명되었다.
하지만 엑셀 데이터 100만건 * N Request를 I/O 처리하기에는 WebFlux 서버로도 무리가 있다는 걸 알 수 있고, 다른 방안이 필요해 보인다.
'백엔드 > Spring' 카테고리의 다른 글
| MySQL Master, Slave Replication(feat. SpringBoot) (1) | 2023.01.11 |
|---|---|
| 멀티 서버 구동시 스케줄러 중복 실행 방지하기 (0) | 2022.07.10 |
| 쿠키, 세션이란? (0) | 2021.01.24 |
| JPA란? (0) | 2020.06.08 |
| Ajax - @RequestBody @ResponseBody에 대해.. (0) | 2019.12.16 |
